
FastText - 개념편
안녕하세요, 이번 포스팅에서는 FastText에 대해서 공부해 보겠습니다.
FastText은 Word2Vec 이후에 나온 Word Embedding 방법인데요.
Google에서 Word2Vec을 개발한 Tomas Micolov님이 Facebook으로 이적하면서 2016년에 새로 개발한 모델입니다.
FastText는 Word2Vec의 단점을 보완하기 위해 제안되었지만, 큰 틀에서는 Word2Vec의 원리를 따르고 있기 때문에 Word2Vec을 공부하셨다면 이해하시는 것이 훨씬 수월하실 것 같습니다. Word2Vec에 대한 자세한 내용을 알고 싶으시다면 여기를 참고해주세요 :)
우수한 성능으로 각광받았던 Word2Vec은 어떤 단점이 있었을까요? 그리고 FastText에서는 이를 어떻게 극복했을까요?
Word2Vec의 한계 - OOV, Infrequent words
Word2Vec 모델은 분산 표현(Distributed representation)을 이용하여 단어를 벡터로 임베딩합니다. 확률 기반의 분산 표현을 이용하면 Vocabulary 안에 있는 단어에 대해서는 확률을 계산할 수 있지만, 단어가 Vocabulary에 있지 않은 경우에는 계산할 수 없습니다. 이러한 단어들을 OOV (Out of vocabulary)라고 합니다. 다시 얘기하면 모델이 배운 적 있는 단어에 대해서는 확률을 계산해서 결과를 낼 수 있지만, 한번도 보지 못한 단어에 대해서는 아무것도 하지 못한다는 겁니다.
예시를 통해서 조금 더 자세히 이해 해보겠습니다. Vocabulary에 ‘Apple’이라는 단어는 있지만, 복수형인 ‘Apples’라는 단어는 없다고 가정해봅시다. 의미가 매우 동일한 두 단어지만, 겨우 철자 하나 차이로 Word2Vec 모델은 Apples에 대해서는 어떠한 결과값도 내지 못합니다.
이와 비슷하게, 데이터셋에는 많은 오탈자들이 포함될 수 있습니다. ‘Applee’과 같이 철자가 하나 더 붙었다거나, ‘Applw’ 과 같이 철자가 하나 틀리는 등 다양한 경우가 있습니다. 이러한 모든 경우들에 대해 Word2Vec은 약세를 보입니다.
또한, Word2Vec에서는 빈도수가 낮은 단어 (Infrequent words)에서도 학습이 잘 되지 않는 단점이 있습니다. 사실, Word2Vec에서도 이 문제점을 인지하고 자주 등장하지 않는 단어들에 대한 학습률을 높이기 위해서 Negative sampling에서 단어 간의 빈도 차이를 조정하는 샘플링 방법을 사용했습니다. 그러나 여전히 Infrequent word에 대해서는 저조한 성적을 보여주고 있습니다.
FastText의 아이디어 - Subwords
Word2Vec에서의 두 가지 한계(OOV, Infrequent word)를 해결하기 위해 FastText에서는 단어 안의 내부단어, 즉 Subword를 고려합니다. Subword는 하나의 단어를 n-gram 방식으로 쪼개는 것을 말합니다. 위에서 복수형에 대한 예를 다시 가져와서 n=5인 방식으로 단어를 쪼갠다고 하면 ‘Apples’는 ‘Apple’, ‘pples’로 쪼개지게 됩니다. 이처럼 단어를 쪼개서 내부 단어로 만들게 되면 Vocabulary에 존재하지 않는 ‘Apples’도 Vocabulary에 존재하는 ‘Apple’이라는 단어를 포함할 수 있기 때문에 ‘Apple’이 임베딩된 벡터를 이용하여 결과물을 낼 수 있게 됩니다. Subword 방식을 이용하면 오탈자에 대한 문제들도 보완이 가능해집니다.
그런데, 단순히 n-gram으로 쪼개기만하면 ‘App’(앱) 이라는 단어와 ‘Apples’에서 tri-gram으로 쪼개진 ‘App’이라는 내부단어(subword)의 구분이 모호해집니다. 이를 방지하기 위해 FastText에서는 단어의 시작과 끝을 의미하는 ‘<’ 와 ‘>’ 를 추가하고 단어 자체를 표기하기위해 기존 단어를 ‘< >’ 로 감싼 형태를 별도로 추가했습니다.
# n = 3인경우 Apple의 subwords
<Ap , App, ppl, ple, les, es>, <Apples>
실제 FastText 모델에서는 n의 범위를 최소값과 최대값 단위로 정의할 수 있도록 했습니다. 기본값인 최소값 = 3, 최대값 = 6 을 적용하면 단어 ‘Apples’는 아래와 같이 쪼개집니다.
# n = 3인경우 Apple의 subwords
<Ap , App, ppl, ple, les, es>, <Appl, pple, ... , <Apples, Apples>, <Apples>
이렇게 쪼개진 Subword들은 각각 분산표현을 통해 임베딩 벡터로 변환되며, Projection layer(hidden layer)에서는 이 subword들이 임베딩된 벡터들의 합으로 word가 표현됩니다.
Apples = <Ap + App + ppl + ... + <Apples, Apples>, <Apples>
아래에서 모델 구조와 함께 조금 더 자세히 살펴 보겠습니다.
FastText 모델 구조
FastText의 모델 구조를 보여드리기에 앞서, Word2Vec의 모델 구조를 간단하게 복습해 보겠습니다. Word2Vec은 아래와 같이 CBOW 또는 Skip-gram 형태로 구성할 수 있었습니다.
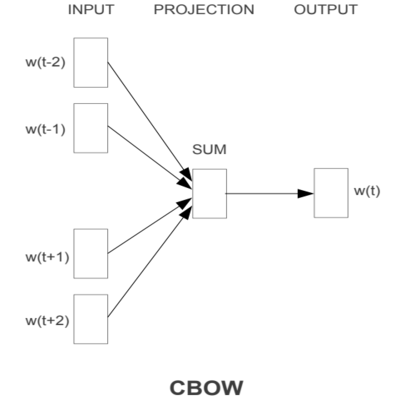
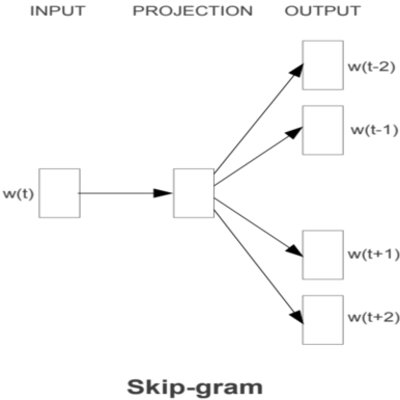
이번 포스팅에서는 Skip-gram 모델을 기준으로 FastText 모델을 설명하도록 하겠습니다. Skip-gram 모델에서는 중심단어(Center word)를 가지고 주변단어(Context word)들을 예측하는 구조입니다. 즉, 중심단어가 Input이 되고 주변단어가 Output이 됩니다.
FastText 모델에서는 아래와 같이 Input으로 중심단어의 각 Subword($x_{1}, x_{2}, …, x_{N}$)들이 들어갑니다.
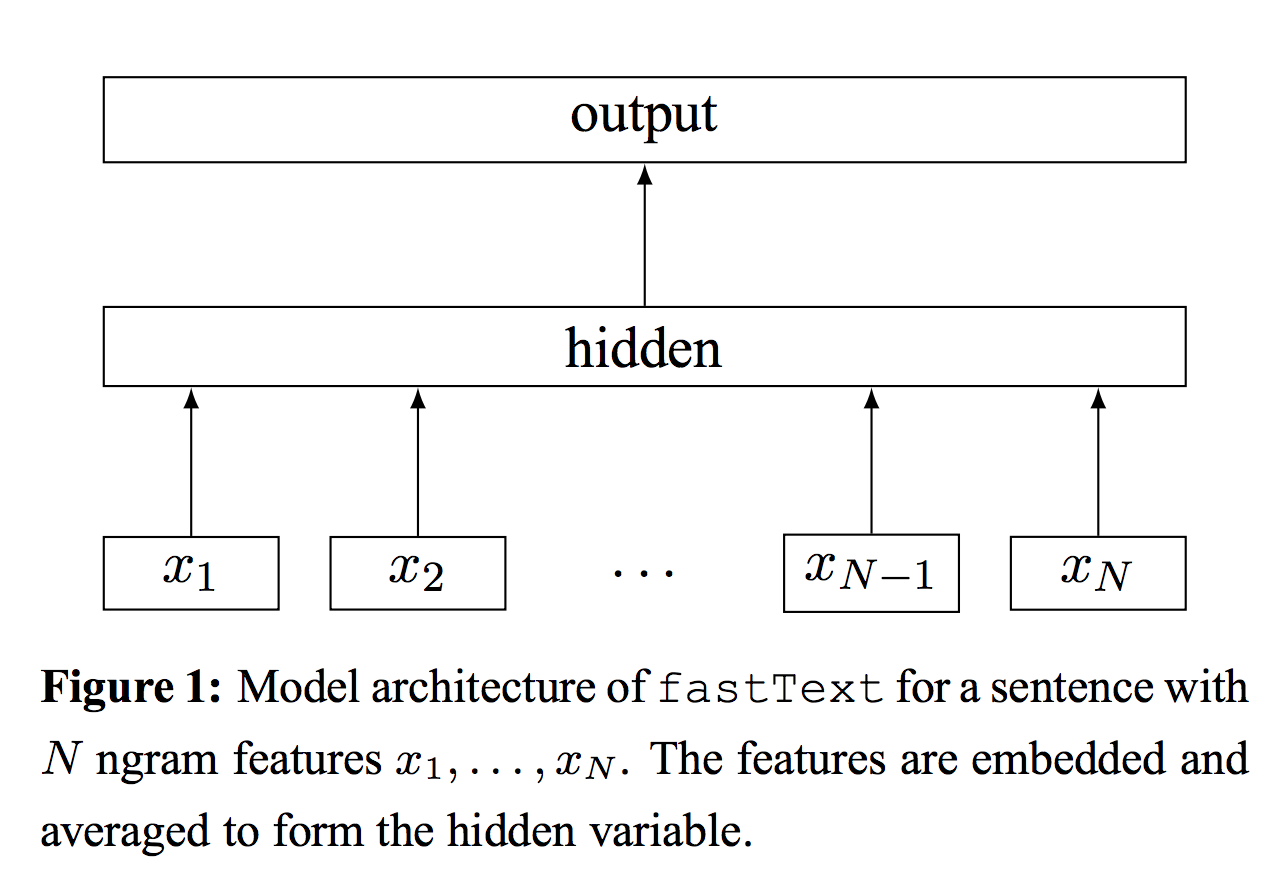 출처 : Fasttext 원문
출처 : Fasttext 원문
각각의 Subword들은 Center matrix에서 look-up table 과정을 거쳐 각각의 임베딩 벡터로 변환되고, 이 벡터들의 평균값을 hidden layer의 임베딩 벡터로서 사용하는 것이죠.
한국어 FastText
FastText를 한국어에 적용하려면 어떻게 할 수 있을까요?
우선 한국어는 영어와 언어 구조적으로 차이가 있기 때문에 subword를 음절 단위와 자소 단위 두가지 방식으로 만들 수 있습니다.
만약 음절 단위로 한국어 단어에 대해 subword를 적용한다면 영어와 동일한 방식으로 적용할 수 있습니다.
# n=3인 tri-gram 적용
자연어처리 = <자연 + 자연어 + 연어처 + 어처리 + 처리>
다음으로, 자소 단위로 한국어 단어에 대해 subword를 적용해 보겠습니다. 이 때 주의할 점은, 한국어는 영어와 달리 초성, 중성, 종성으로 나누어지므로 이에 대한 구분을 명확히 해 주어야만 합니다.
# 단어를 자소 단위로 쪼개기
자연어처리 = ㅈ, ㅏ, ㅇ, ㅕ, ㄴ, ㅇ, ㅓ, ㅊ, ㅓ, ㄹ, ㅣ
위와 같이 한글 단어를 자음과 모음으로 쪼갤 때, 이를 다시 원래의 단어로 만들기 위해서는 각 음절단위에서 종성의 유무가 굉장히 중요한 정보가 됩니다. 따라서, 각 음절에 종성이 존재하지 않을 때 특별한 토큰 ‘_‘을 추가해 주면, 한 음절은 3개의 자소단위 토큰으로 구성할 수 있습니다.
# 단어를 자소 단위로 쪼개고 초성, 중성, 종성으로 구분하기
자연어처리 = ㅈ ㅏ _ ㅇ ㅕ ㄴ ㅇ ㅓ _ ㅊ ㅓ _ ㄹ ㅣ _
# Subword 적용
자연어처리 = <ㅈㅏ + ㅈㅏ_ + ㅏ_ㅇ + ... + ㅊㅓㄹㅣ> + <ㅈㅏ_ㅇㅕㄴㅇㅓ_ㅊㅓ_ㄹㅣ_>
한국어의 경우, Subword 를 음절 단위로 만드느냐 자소 단위로 만드느냐에 따라서 분명한 차이가 있을테지만, 어떤 Task에 적용되느냐에 따라서도 모델의 성능이 크게 좌우될 것으로 예상됩니다.
따라서, 두 가지 방식 모두 적용한 후에 비교를 하면서 더 좋은 성능을 내는 쪽으로 선택하면 되지 않을까 싶습니다.
마치며
이번 포스팅에서는 FastText에 대해 공부하면서 Word2Vec의 한계점과 이를 어떻게 개선할 수 있었는지 알아보았습니다.
다음 포스팅에서는 Skip-gram모델을 기반으로 한국어 FastText를 직접 구현해보도록 하겠습니다.
Comments