
Neural probabilistic language model (nplm) pytorch로 구현하기
안녕하세요, 이번 포스팅에서는 저번 시간에 공부한 NPLM 모델을 직접 구현해보도록 하겠습니다.
일반적으로 구현을 할 때는 전체적인 흐름을 미리 생각하고 구현을 하기 때문에 함수나 모델에 대한 정의를 미리 하는데, 저는 그렇게 했을 때 이해하기가 조금 더 어려움을 느꼈습니다.
그래서, 여러분들이 글을 읽고 따라오시면서 최대한 쉬운 이해를 하실 수 있도록 의식의 흐름대로 구현을 한 후에, 마지막에 전체적으로 코드를 정리하도록 하겠습니다.
Import Library
먼저, 기본 라이브러리들을 import 하겠습니다. pytorch와 neural network, 그리고 학습하면서 weight update를 하기 위한 optimizer를 가져옵니다.
import torch
import torch.nn as nn
import torch.optim as optim
저는 모델을 만들기 전에 우선 ‘데이터’에 대한 이해와 준비가 필요하다고 생각합니다. 데이터가 정확히 어떤 형식으로 준비되어야 하는지 알지 못한다면 모델이나 함수를 구현할때 더욱 헷갈리는 것 같습니다.
직관적인 이해를 위해 오픈 데이터셋을 사용하지 않고, 간단한 몇 개의 문장으로 데이터를 준비해 보겠습니다.
우선, NPLM은 n-gram을 기반으로 하기 때문에 n을 정해 보겠습니다. 대부분 n-gram에서 n=3으로 하는 tri-gram을 많이 사용하기 때문에, 3개의 어절로 구성된 문장들을 준비했습니다.
corpus = ['코딩은 시작이 반이다', '나는 오늘도 주짓수', '코딩은 어려워 짜증나', 'NLP 니가 뭔데', '내가 바로 공주다']
위에서 준비한 이 문장들이 우리가 확보한 dataset, 즉 corpus(말뭉치)가 됩니다.
Tokenization(토큰화)
다음으로, 문장으로 구성된 데이터 셋을 단어 단위로 쪼개는 Tokenization(토큰화) 과정이 필요합니다.
이번 포스팅에서 준비한 corpus는 띄어쓰기를 기준으로 아주 간단하게 Tokenization을 진행할 수 있지만, 사실 실제 대용량 데이터를 다룰 때에는 중복 단어, 특수 문자, 띄어쓰기, 불필요한 단어, 오타 등을 처리하기 위해 다양한 전처리 과정들을 반드시 진행해야 합니다.
전처리까지 다루기에는 너무 복잡해지므로 본 포스팅에서는 띄어쓰기를 기준으로 간단히 단어를 나누고, 중복되는 단어만 제거하는 방식으로 토큰화를 진행하겠습니다.
tokens = " ".join(corpus).split() # " "(띄어쓰기)를 기준으로 corpus 안의 데이터를 split(분리)해줍니다.
tokens = list(set(tokens)) # set 함수는 중복 없이
위와 같이 띄어쓰기를 기준으로 단어들을 구분한후, 단어들을 모두 모았습니다. corpus가 준비되었으니, 각 단어의 인덱스를 만들어 주겠습니다. 인덱싱은 dictionary를 활용하여 단어를 알 때 인덱스를 찾거나, 인덱스를 알 때 단어를 찾을 수 있도록 두가지를 만들어 줍니다.
word_dict = {w: i for i, w in enumerate(tokens)} # word -> index
index_dict = {i: w for i, w in enumerate(tokens)} # index -> word
word_dict
{'어려워': 0,
'짜증나': 1,
'바로': 2,
'나는': 3,
'주짓수': 4,
'NLP': 5,
'내가': 6,
'코딩은': 7,
'반이다': 8,
'니가': 9,
'공주다': 10,
'오늘도': 11,
'시작이': 12,
'뭔데': 13}
index_dict
{0: '어려워',
1: '짜증나',
2: '바로',
3: '나는',
4: '주짓수',
5: 'NLP',
6: '내가',
7: '코딩은',
8: '반이다',
9: '니가',
10: '공주다',
11: '오늘도',
12: '시작이',
13: '뭔데'}
Input / Output 나누기
다음으로, input과 target을 나눠주겠습니다. 우리의 목적은 단어 2개를 참고하여 그 다음에 올 단어를 예측하는 것입니다(tri-gram). 각 단어들을 추출한 후에, 추후 Embedding을 진행하기 위해 미리 word_dict를 이용하여 인덱스로 변환해주도록 하겠습니다. 마지막으로, 모델에 들어가는 input 형태는 tensor 타입으로 들어가기 때문에 최종 출력을 tensor타입으로 변환해 줍니다.
def make_input_target():
input_batch = []
target_batch = []
for sentence in corpus:
word = sentence.split() # 띄어쓰기 기준으로 단어 구분
input = [word_dict[n] for n in word[:-1]] # 1 ~ n-1 번째 단어를 input으로 사용. n=3이므로 첫 두 단어 사용
target = word_dict[word[-1]] # n번째 단어를 target으로 사용
input_batch.append(input)
target_batch.append(target)
return torch.LongTensor(input_batch), torch.LongTensor(target_batch)
input과 target이 인덱스를 기준으로 잘 정리 되었는지 확인해보겠습니다.
input_batch, target_batch = make_input_target()
print('Input : ', input_batch)
print('Target : ', target_batch)
Input : tensor([[ 7, 12],
[ 3, 11],
[ 7, 0],
[ 5, 9],
[ 6, 2]])
Target : tensor([ 8, 4, 1, 13, 10])
Model
임베딩 과정부터는 모델 안에서 다루어지는데요,
먼저 모델에 사용되는 각 요소들에 대해서 한번 더 짚고 넘어가겠습니다.
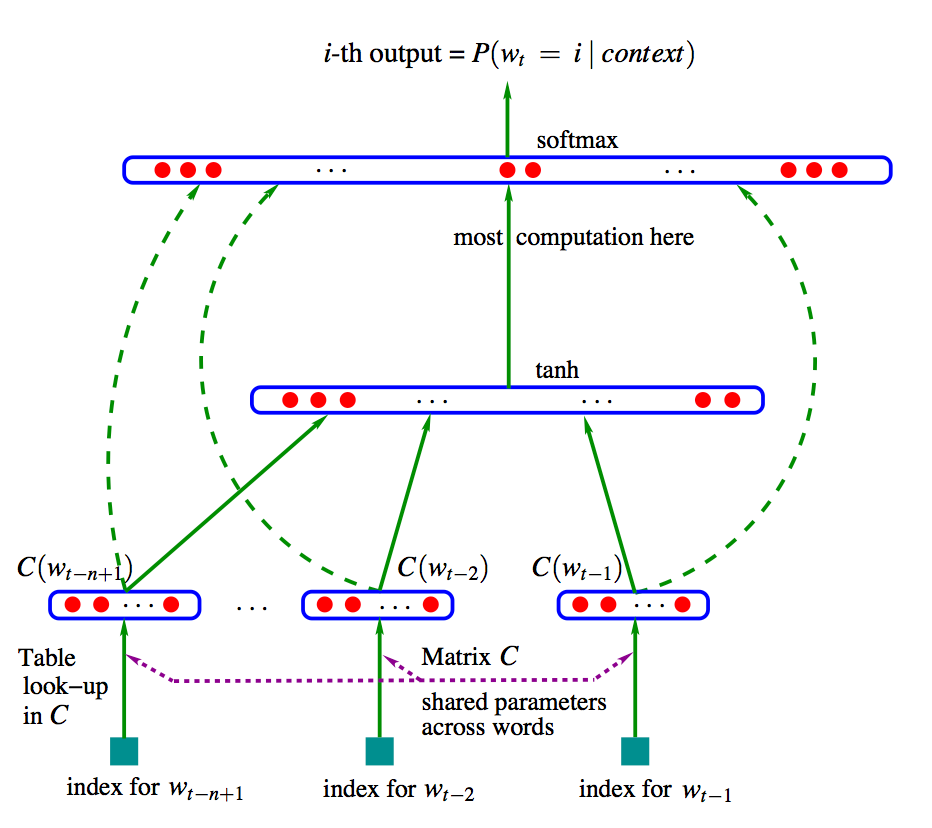
target을 예측하기 위한 output 수식은 $Y_{w_{t}} = b + Wx + U( tanh(Hx_{t}+d) )$ 였습니다.
V : 총 토큰(단어) 개수
m : 임베딩 벡터 차원 (단어를 몇 차원의 벡터로 임베딩할건지 결정. 예를 들어 m=2이면 2차원의 벡터가 생성됨)
n_hidden : hidden layer의 unit 수
C (Embedding matrix) : 각 인덱스에 있는 단어가 embedding되어 vector 형태로 들어 있음. 차원 = V x m
H : Embedding matrix와 hidden layer 사이의 weight. 차원 = ( (n-1) * m ) x n_hidden
d : hidden layer의 bias. 차원 = n_hidden
U : hidden layer가 activation function (tanh)까지 거친 후와 output 사이의 weight. 차원 = n_hidden x V
W : Embedding layer에서 output까지 직접 연결하기 위한 weight. 차원 = ( (n-1) * m ) x V
b : 가장 마지막에(out 직전에) 더해주는 bias.
$w_{t}$ : 문장에서 t번째 단어
$x_{t}$ : 문장에서 t번째 단어가 C (Embedding matrix)를 거쳐 임베딩 된 형태. C($w_{t}$)와 동일
class NPLM(nn.Module):
def __init__(self):
super(NPLM, self).__init__()
self.C = nn.Embedding(V, m)
self.H = nn.Linear( (n-1)*m, n_hidden, bias=False)
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear( n_hidden, V, bias=False)
self.W = nn.Linear( (n-1)*m, V, bias=False)
self.b = nn.Parameter(torch.ones(V))
def forward(self, X):
X = self.C(X) # 인덱스 -> embedding vector
X = X.view(-1, (n-1)*m) # (n-1)개의 embedding vector를 unroll 하여 [batch_size x (n-1)*m] 으로 만들어줌
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, V]
return output
자, 이렇게 모델도 구축을 완료했습니다! 이제, 모든 요소들을 포함한 메인 루프를 완성해 봅시다 : )
Main
if __name__ == '__main__': #코드를 직접 실행했을때만 작동하고, import 될때는 작동하지 않게 만들어줌
n = 3
n_hidden = 2
m = 2
V = len(tokens)
model = NPLM()
criterion = nn.CrossEntropyLoss() # loss function으로 cross entropy 사용
optimizer = optim.Adam(model.parameters(), lr=0.001) # optimizer로 adam 사용
input_batch, target_batch = make_input_target()
# Training
for epoch in range(10000):
optimizer.zero_grad() # optimizer 초기화
output = model(input_batch) # output 계산
loss = criterion(output, target_batch) # loss 계산
if (epoch+1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch+1), 'cost =', '{:.6f}'.format(loss)) #1000번째 epoch마다 loss 출력
loss.backward() # backpropagation
optimizer.step() # weight update
Epoch: 1000 cost = 0.063062
Epoch: 2000 cost = 0.013515
Epoch: 3000 cost = 0.005067
Epoch: 4000 cost = 0.002322
Epoch: 5000 cost = 0.001171
Epoch: 6000 cost = 0.000622
Epoch: 7000 cost = 0.000341
Epoch: 8000 cost = 0.000190
Epoch: 9000 cost = 0.000107
Epoch: 10000 cost = 0.000061
모델 학습이 잘 된 것 같습니다!
그럼 이제 예측 결과를 살펴볼까요?
# Prediction
predict = model(input_batch).data.max(1, keepdim=True)[1]
for i in corpus:
print(i.split()[:n-1], ' -> ', i.split()[-1])
['코딩은', '시작이'] -> 반이다
['나는', '오늘도'] -> 주짓수
['코딩은', '어려워'] -> 짜증나
['NLP', '니가'] -> 뭔데
['내가', '바로'] -> 공주다
앞의 두 단어를 이용해서 뒤의 단어를 잘 예측하는 것을 확인할 수 있습니다.
Embedded word scatter plot
또 하나, 재밌는 것을 확인해보고자 합니다. 학습된 embedding vector들을 2차원 평면상에 뿌려보았을때, 서로 관련있는 단어들끼리 뭉쳐질까요?
from matplotlib import pyplot as plt
plt.rc('font', family='Malgun Gothic') # 한글 출력을 가능하게 만들기
plt.rc('axes', unicode_minus=False) # 한글 출력을 가능하게 만들기
fig, ax = plt.subplots()
ax.scatter(model.C.weight[:,0].tolist(), model.C.weight[:,1].tolist())
for i, txt in enumerate(tokens):
ax.annotate(txt, (model.C.weight[i,0].tolist(), model.C.weight[i,1].tolist()))
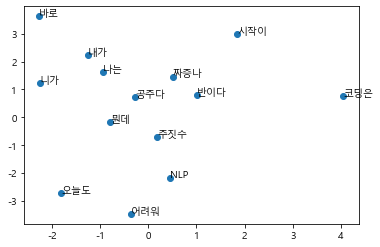
평면상에 표상은 되었다만 딱히 큰 연관성은 보이지 않는 것 같습니다. 풍부한 데이터를 이용하여 학습시킨다면 품사 간의 관계나 단어의 유의성 등을 훨씬 잘 표상하지 않을까 싶습니다.
Whole code
마지막으로, 전체 코드 정리본을 올리고 마무리하겠습니다.
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
def make_input_target():
input_batch = []
target_batch = []
for sentence in corpus:
word = sentence.split() # 띄어쓰기 기준으로 단어 구분
input = [word_dict[n] for n in word[:-1]] # 1 ~ n-1 번째 단어를 input으로 사용. n=3이므로 첫 두 단어 사용
target = word_dict[word[-1]] # n번째 단어를 target으로 사용
input_batch.append(input)
target_batch.append(target)
return torch.LongTensor(input_batch), torch.LongTensor(target_batch)
class NPLM(nn.Module):
def __init__(self):
super(NPLM, self).__init__()
self.C = nn.Embedding(V, m)
self.H = nn.Linear( (n-1)*m, n_hidden, bias=False)
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear( n_hidden, V, bias=False)
self.W = nn.Linear( (n-1)*m, V, bias=False)
self.b = nn.Parameter(torch.ones(V))
def forward(self, X):
X = self.C(X) # 인덱스 -> embedding vector
X = X.view(-1, (n-1)*m) # (n-1)개의 embedding vector를 unroll 하여 [batch_size x (n-1)*m] 으로 만들어줌
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, V]
return output
if __name__ == '__main__': #코드를 직접 실행했을때만 작동하고, import 될때는 작동하지 않게 만들어줌
corpus = ['코딩은 시작이 반이다', '나는 오늘도 주짓수', '코딩은 어려워 짜증나', 'NLP 니가 뭔데', '내가 바로 공주다']
tokens = " ".join(corpus).split() # " "(띄어쓰기)를 기준으로 corpus 안의 데이터를 split(분리)해줍니다.
tokens = list(set(tokens)) # set 함수는 중복 없이
word_dict = {w: i for i, w in enumerate(tokens)} # word -> index
index_dict = {i: w for i, w in enumerate(tokens)} # index -> word
n = 3
n_hidden = 2
m = 2
V = len(tokens)
model = NPLM()
criterion = nn.CrossEntropyLoss() # loss function으로 cross entropy 사용
optimizer = optim.Adam(model.parameters(), lr=0.001) # optimizer로 adam 사용
input_batch, target_batch = make_input_target()
# Training
for epoch in range(10000):
optimizer.zero_grad() # optimizer 초기화
output = model(input_batch) # output 계산
loss = criterion(output, target_batch) # loss 계산
if (epoch+1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch+1), 'cost =', '{:.6f}'.format(loss)) #1000번째 epoch마다 loss 출력
loss.backward() # backpropagation
optimizer.step() # weight update
# Prediction
predict = model(input_batch).data.max(1, keepdim=True)[1]
for i in corpus:
print(i.split()[:n-1], ' -> ', i.split()[-1])
# Scatter embedded vectors
plt.rc('font', family='Malgun Gothic') # 한글 출력을 가능하게 만들기
plt.rc('axes', unicode_minus=False) # 한글 출력을 가능하게 만들기
fig, ax = plt.subplots()
ax.scatter(model.C.weight[:,0].tolist(), model.C.weight[:,1].tolist())
for i, txt in enumerate(tokens):
ax.annotate(txt, (model.C.weight[i,0].tolist(), model.C.weight[i,1].tolist()))
Comments