
TextCNN - 개념편
안녕하세요, 이번 포스팅에서는 TextCNN에 대해서 공부해 보겠습니다.
TextCNN은 2014년에 Yoon Kim 교수님께서 제안하셨으며, CNN(Convolutional Neural Network)모델을 Text에 적용한 모델입니다.CNN을 이용하여 문장의 정보를 함축적으로 학습하여 문장 분류 테스크에서 RNN기반 모델보다 뛰어난 성능을 낼 수 있었습니다. 원문 제목은 Convolutional Neural Networks for Sentence Classification입니다.
아마 TextCNN을 처음 접하신 분들은 ‘이미지나 영상 분류쪽에 특화된 CNN 모델을 어떻게 텍스트에 적용한거지?’ 라는 의문이 드실 겁니다. 이번 포스팅에서는 어떻게 CNN 모델을 텍스트에 적용하여 문장의 전체적인 정보를 함축해낼 수 있는지 천천히 살펴보겠습니다.
CNN에서는 이미지에서 공간적인 정보를 함축적으로 이해하기 위해서 convolutional filter를 적용합니다.
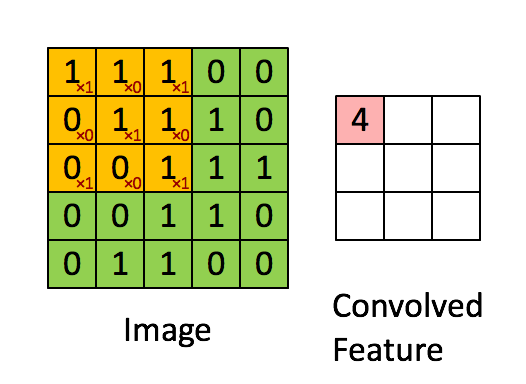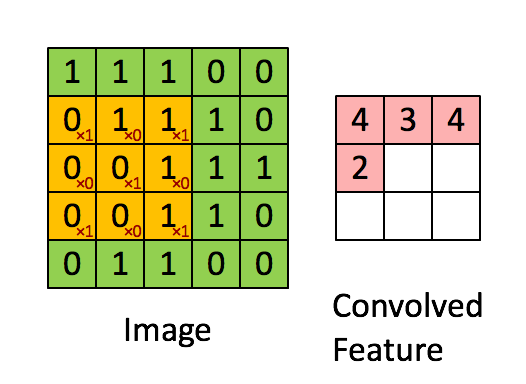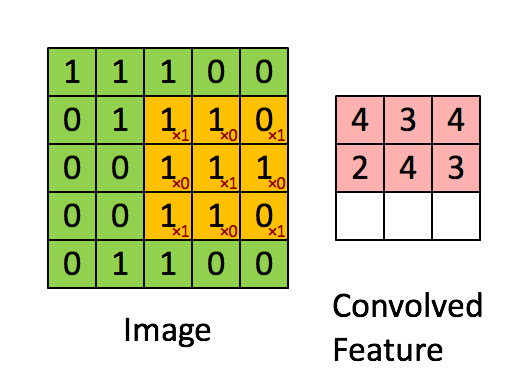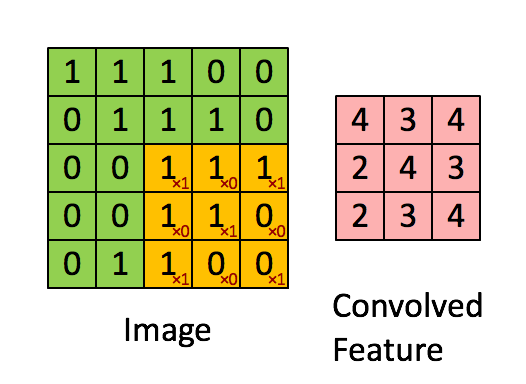
노란색으로 표시된 convolutional filter가 움직이면서 Image의 각 픽셀값들과 내적 연산을 한 후 Feature map(또는 convolved Feature)을 만들어 냅니다. 이후 Activation, Max Pooling 기법을 통하여 Feature map 안에서도 가장 중요한 값만 뽑아 냅니다. 이 과정을 통해 CNN 모델은 이미지의 각 공간들을 압축하여 엑기스 정보들만 뽑아낼 수 있습니다.
TextCNN에서도 CNN에서의 핵심 개념인 Convolutional filter를 적용하여 각 문장에서 각 단어들의 순서 및 문맥으로부터 정보를 압축해낼 수 있습니다.
단어 임베딩 (Word Embedding)
자연어 처리 분야에서 단어를 n차원의 실수로 이루어진 벡터로 변환하는 것을 임베딩(Embedding) 이라고 합니다. 아래 예시는 각 단어를 3차원의 벡터로 임베딩 한 것을 보여줍니다.
# Word Embedding Examples
'I' = [0.1 0.4 2.1]
'love' = [0.2 0.1 1.3]
'you' = [1.1 3.2 2.9]
그렇다면, ‘I love you’라는 문장이 주어지면 각 단어들을 임베딩하면 3 x 3 짜리 단어 배열을 얻을 수 있겠죠? 이 때, 각 문장의 단어 개수를 ‘시퀀스 길이 (Sequence length)’ 라고 합니다.
각 문장에 Convolutional filter 적용하기
단어 임베딩을 조금 더 일반적으로 확장하여 생각해 봅시다. 임베딩 차원을 p차원으로 하고 각 문장에 포함된 단어 길이를 n이라고 했을 때, 해당 문장은 n x p 차원의 배열로 변환됩니다. 여기에, 2 x p 사이즈를 가지는 convolutional filter를 적용하게 되면 아래 움짤과 같이 문장에서도 convolution 연산을 수행할 수 있게 됩니다. 이미 눈치 채셨을 수도 있지만, filter size가 [h x p]일때 h는 한번에 몇 개의 단어를 동시에 볼 것인지를 의미하며, p는 고정으로 사용합니다.
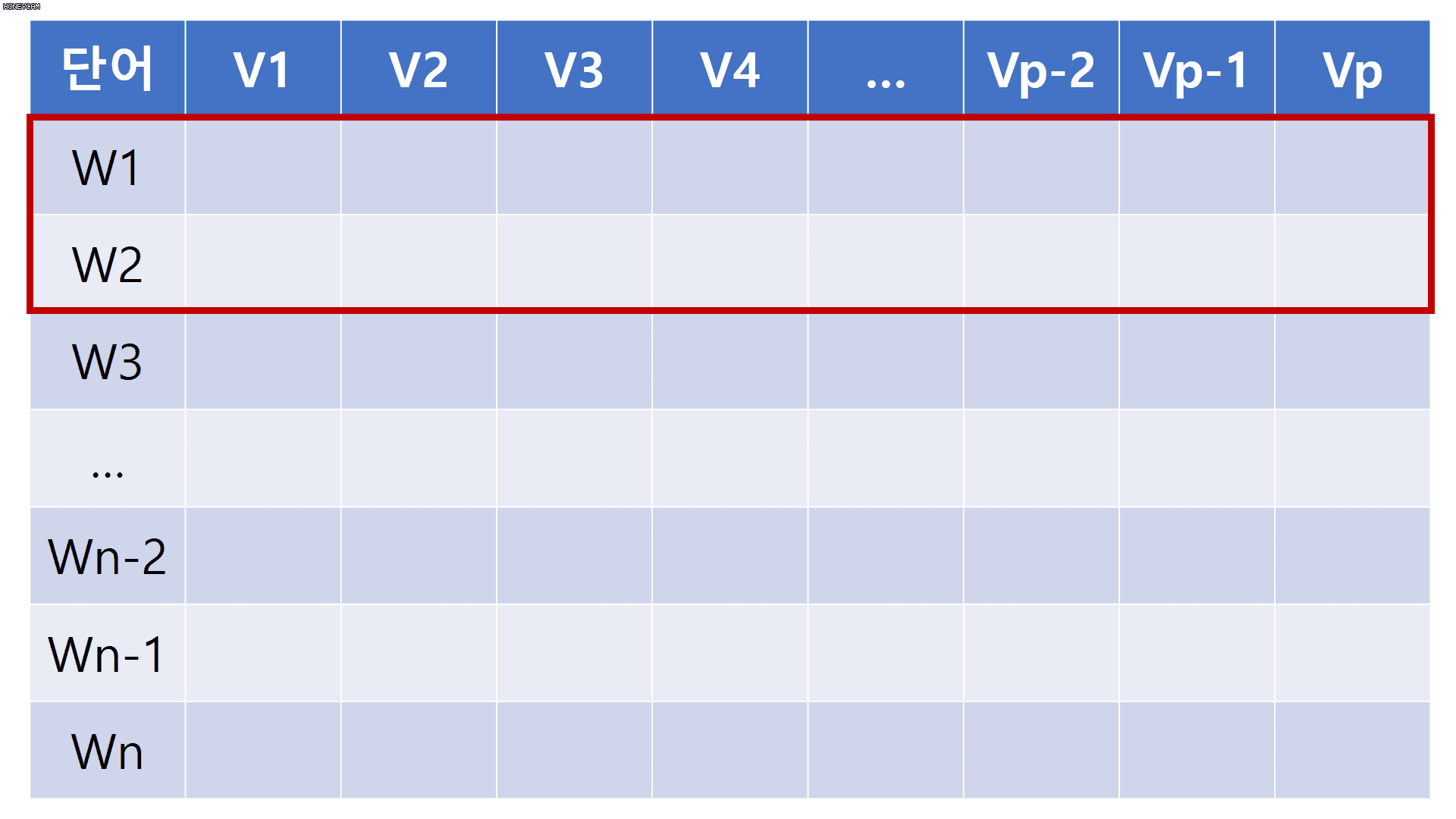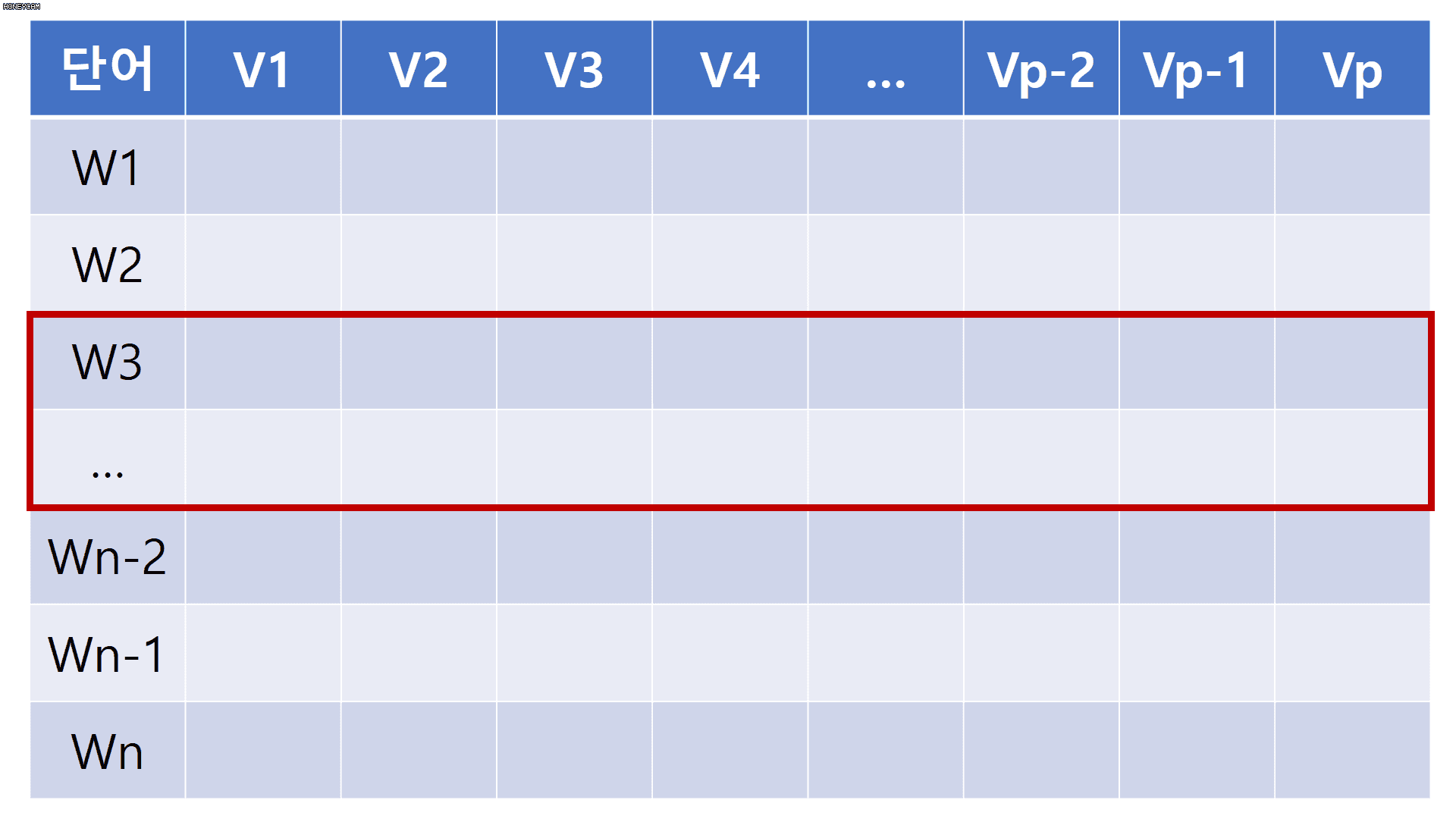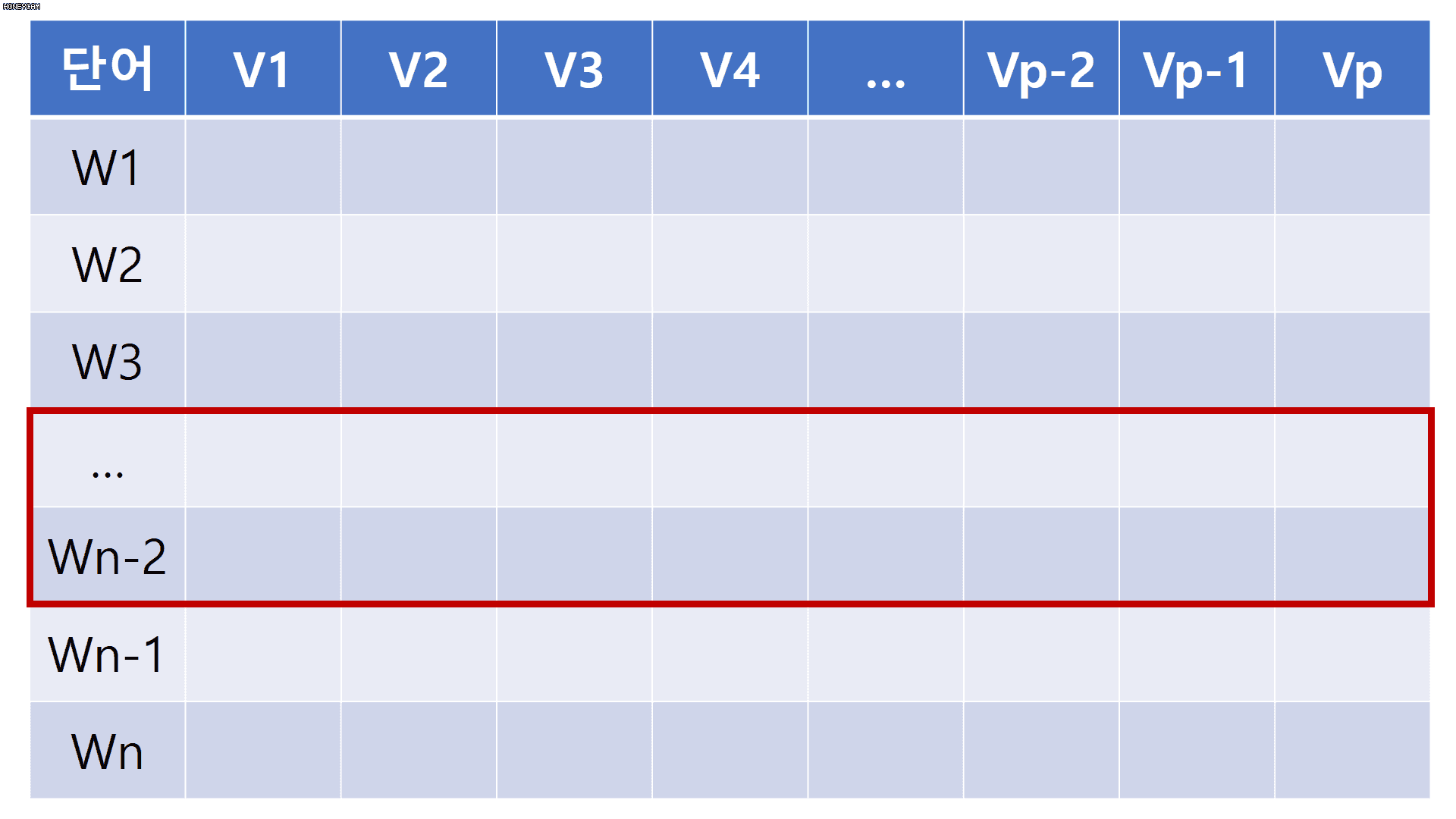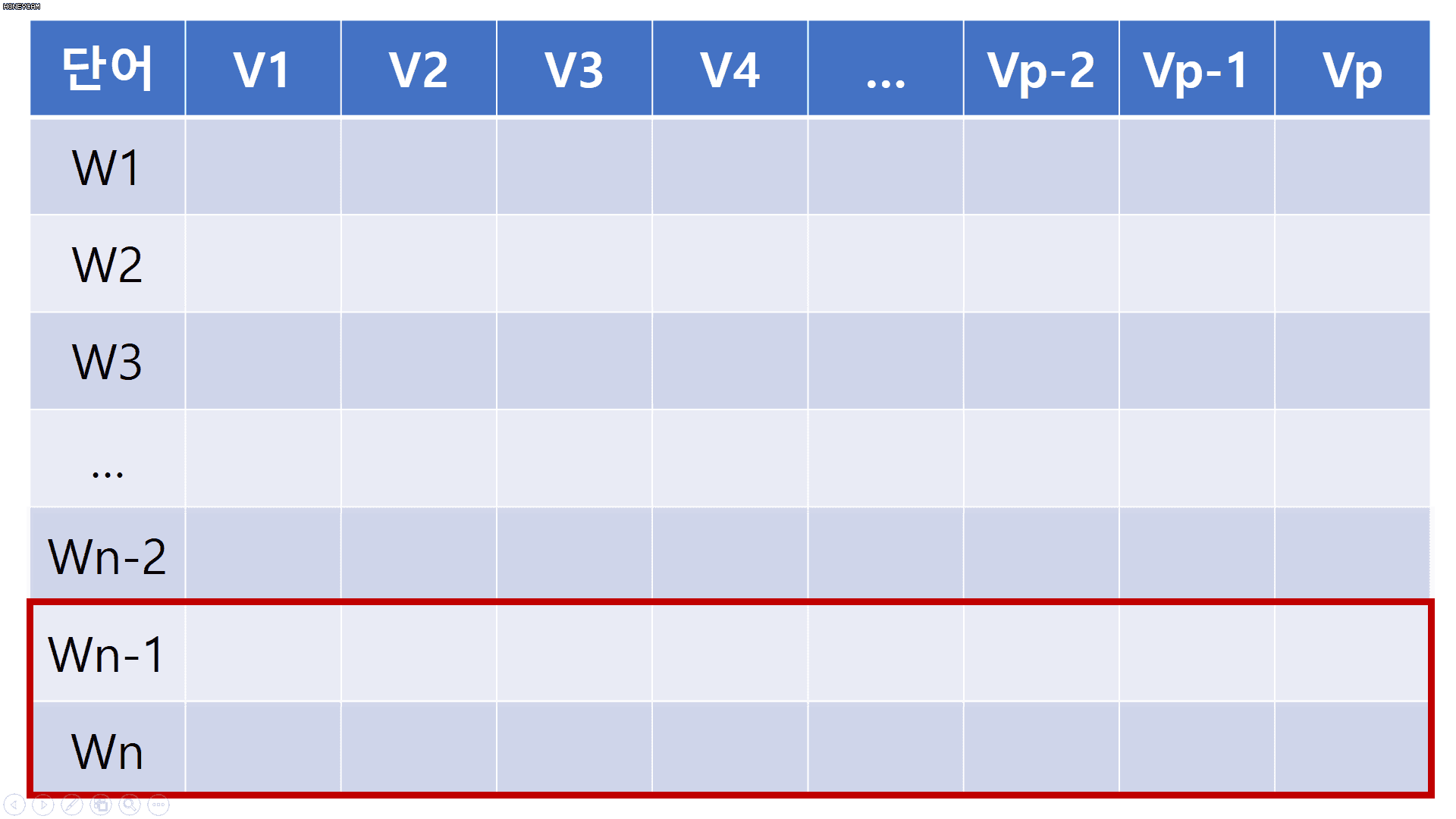
단어 임베딩을 통해 각 문장에서 convolution 연산 수행이 가능하다는 것을 이해했으니, 원 논문에서는 어떻게 모델을 구성했는지 자세히 살펴보러 갑시다.
TextCNN
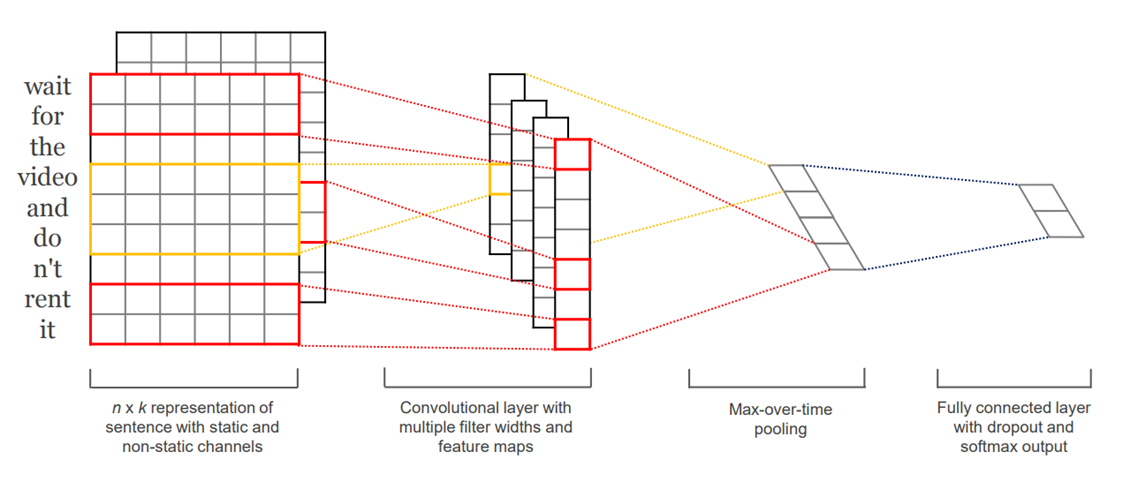
위 그림은 TextCNN에서 제안한 모델 아키텍쳐입니다. ‘Wait for the video and don’t rent it’이라는 문장을 n개의 단어로 쪼갠 후, k차원의 임베딩을 하여 n x k 짜리 배열을 만든 것을 확인할 수 있습니다.
원문에서는 각 문장을 static과 non-static channel 두 가지로 만든 것을 보여주고 있는데요. static channel은 Word2Vec과 같이 사전에 학습된 임베딩 벡터들을 사용하면서 TextCNN 모델 학습중에도 해당 임베딩 벡터들을 업데이트 하지 않고 고정하는 것을 말하며, non-static channel은 TextCNN 모델을 학습하면서 해당 임베딩 벡터들을 추가로 학습시키면서 업데이트 하는 것을 의미합니다.
다음으로, 각 n x k 배열에 h x k 크기의 필터를 적용하여 convolutional 연산을 수행합니다. 원문에서는 filter size를 2 x k , 3 x k , 4 x k 총 3가지 종류를 적용하여 각각 convolutional 연산을 수행했습니다. 다시 말해, 한번에 볼 수 있는 단어 개수를 2가지, 3가지, 4가지로 설정하여 학습을 할 수 있도록 구성한 것이죠.
Convolution 연산을 통해서 만들어진 feature map은 Activation function을 통해 변환된 후, Max pooling 기법을 사용하여 가장 큰 값들만 추출됩니다. 마지막으로 이 값들을 하나로 이어 붙여 Fully connected layer의 input으로 넣어주게 됩니다.
원문의 아키텍처에는 다소 생략된 부분이 있어, 다른 그림을 통해 좀 더 자세히 살펴보도록 하겠습니다.
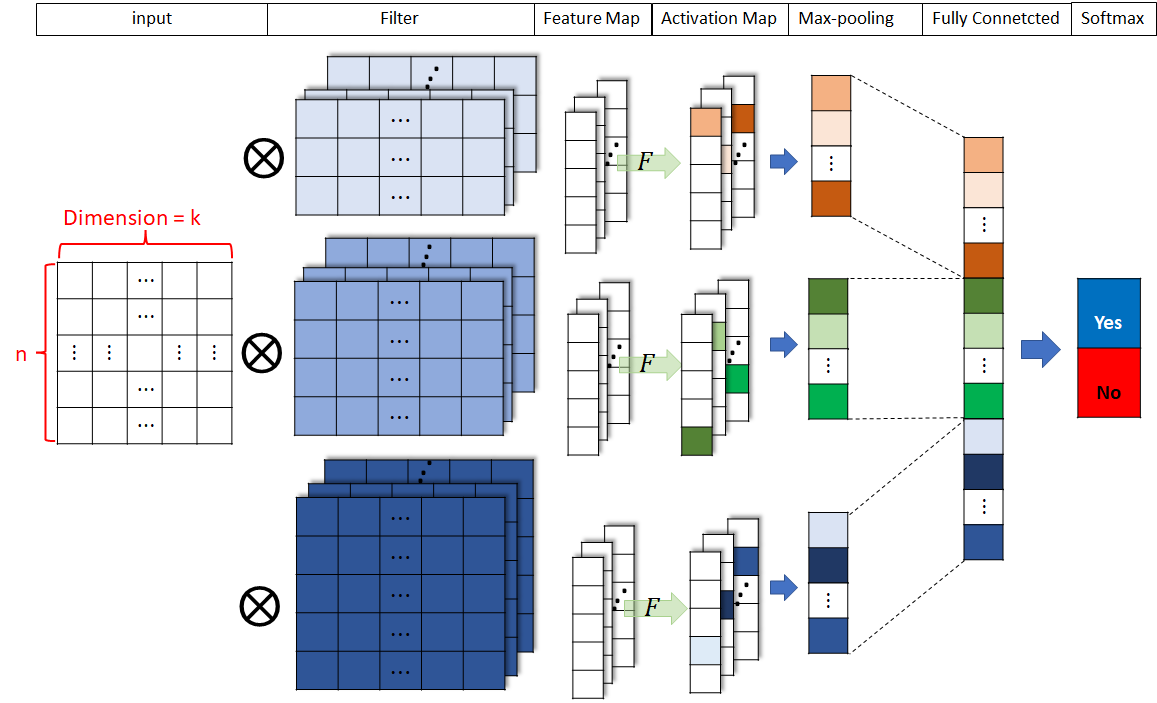
위 그림에서는 n x k 으로 변환된 문장에 각각 3 x k, 4 x k, 5 x k 크기의 filter를 적용한 것을 알 수 있습니다. 여기서 필터 크기는 같지만 값들은 서로 다른 여러개의 필터를 적용하여 여러개의 feature map을 뽑아 냅니다.
각 feature map들은 Activation function을 통해 Activation map으로 변환됩니다. 다음으로, 각 필터 크기별로 Activation map에 max pooling을 적용하여 뽑힌 값들을 모두 이어붙여 Fully connected layer의 input으로 넣어주게 됩니다.
예를 들어, 위의 그림처럼 3종류의 필터를 사용하고 각 필터를 5개씩 적용하면 각 필터 종류별로 5개의 Activation map을 얻을 수 있고, max pooling을 적용하여 모두 이어붙이면 3 * 5 = 15차원의 벡터를 얻을 수 있습니다. 최종적으로 softmax를 통해 binary class에 대한 prediction을 하도록 구성되어 있는 것을 알 수 있습니다.
이처럼 TextCNN을 활용하면 문장 안에 있는 단어들의 순서 및 문맥을 압축하여 문장이 긍정적인지 부정적인지 분류하는 등의 테스크에서 좋은 성능을 낼 수 있습니다.
마치며
이번 포스팅에서는 TextCNN의 개념에 대해서 공부했습니다. 다음 포스팅에서는 TextCNN을 pytorch로 직접 구현하여 문장이 긍정적인지 부정적인지 분류하는 모델을 만들어보도록 하겠습니다. 그럼, 다음 포스팅에서 뵙겠습니다!
References
Convolutional Neural Networks for Sentence Classification
딥러닝 도전기 님의 블로그
ratsgo 님 블로그
CS231n - CNN 강의자료
Comments