
VQ-Wav2vec 논문 꼼꼼 리뷰 - 2편
VQ-Wav2vec: Self-supervised learning of discrete speech representations
저번 포스팅에서는 VQ-Wav2vec의 모델 구조에 대해서 자세히 알아봤는데요, 이번 포스팅에서는 VQ-Wav2vec을 훈련한 이후에 quantized representation을 활용하여 BERT 모델을 학습하는 과정과, BERT까지 학습을 마친 후 output을 이용해서 최종적으로 Acoustic Model(AM)을 훈련시킨 결과에 대해 얘기해보려고 합니다.
BERT(Bi-directional Encoder Representations from Transformer)
BERT는 transformer encoder를 토대로 MLM(masked language modeling)을 적용한 모델입니다. BERT는 모든 자연어 처리 task에서 좋은 성능을 내어 큰 화제가 되었으며, 현재까지도 많은 변형모델들을 통해 많은 사랑을 받고 있습니다. 저자들은 이처럼 잘 알려진 BERT를 활용하여 음성인식을 위한 audio representation을 학습시켜보고 싶었던 것이죠. 다만, BERT는 input을 이산화된(discretized) 형태로 받고 있기 때문에 저자들은 기존 wav2vec에 quantized module을 적용하여 BERT의 input으로 쓸 수 있게 만들었습니다.
저자들은 BERT에서 사용하는 MLM(masked language modeling) 방법을 적용했습니다. 아래 그림과 같이 input token에 특정 비율로 mask를 씌워 가린 후에, 해당 부분에 어떤 token이 들어갈지 예측하도록 학습시키는 방법입니다. VQ-Wav2vec에서는 quantized된 representation을 사용하면 약 10ms정도의 audio신호를 반영하게 되는데, 기존 BERT에서 사용하는 방식을 그대로 적용하면 맞추기가 너무 쉽다고 합니다. 그래서 저자들은 난이도를 높이기 위해 10개의 연속적인(span) mask 토큰을 도입했습니다. 이로 인해 기존 단일 token의 masking을 학습하는 것보다 더 성능을 향상시킬 수 있었다고 합니다.
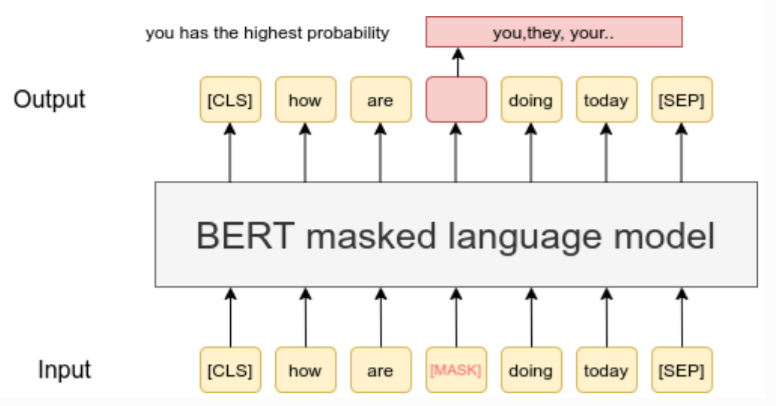
EXPERIMENT
저자들은 vq-wav2vec과 BERT의 pre-train을 위해 960시간짜리 Librispeech를 사용했습니다. 최종 모델 평가는 TIMIT dataset과 Wall Street Journal(WSJ) 데이터셋을 사용했습니다. 원문에서 저자들은 실험 조건에 따라 훈련 조건도 조금씩 차이를 두었고, BERT모델도 base버전과 large버전으로 나누었습니다. 실험조건에 대한 자세한 내용이 궁금하시다면 VQ-Wav2vec 원문의 Experiment 파트를 직접 참고하시길 추천드립니다.
VQ-Wav2vec의 파이프라인에서 마지막에 있는 Acoustic model로는 wav2vec 모델과 동일하게 facebook의 wav2letter를 사용하였으며, 언어 모델은 WSJ 데이터로만 학습된 4-gram KenLM과 character based convolutional LM을 사용했습니다.
RESULT
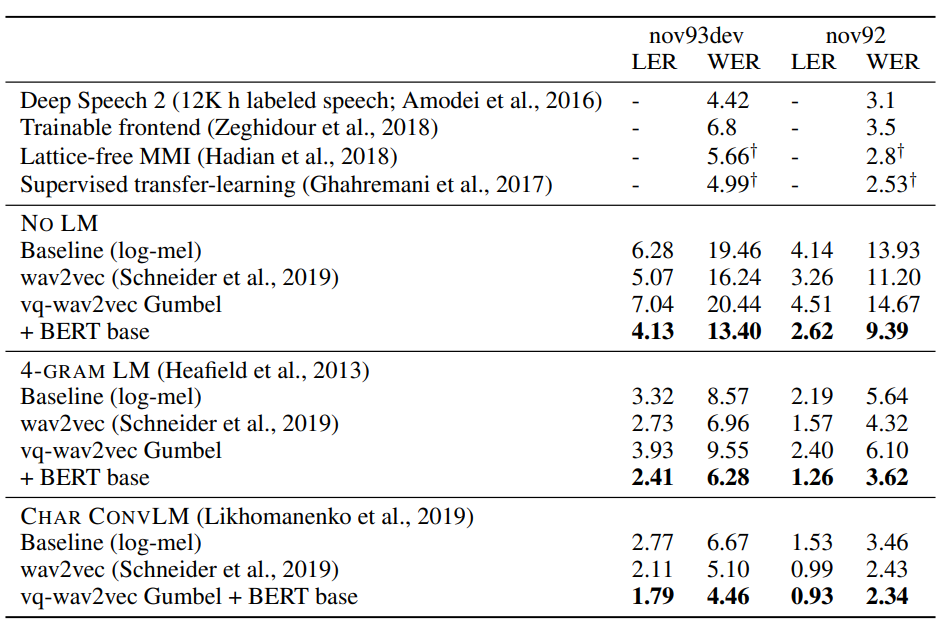
실험 결과를 3가지로 요약하면 아래와 같습니다.
- 기존 log-mel spectrogram을 인풋으로 사용하는 SOTA모델인 DeepSpeech2 보다 뛰어난 성능을 보였습니다.
- Discretized token을 사용하여 BERT를 훈련시킨 후에 BERT의 output을 Acoustic model에 적용한 방식이 기존 wav2vec보다 성능이 좋았습니다.
- Quantization module에 사용한 두가지 방법 중 Gumbel-Softmax가 K-mean clustering보다 성능이 좋았습니다.
CONCLUSION
지금까지 VQ-wav2vec에 대해서 알아보았습니다. VQ-wav2vec를 통해 음성인식에서도 BERT를 활용하여 좋은 성능을 낼 수 있다는 것을 알 수 있었고, BERT를 적용하기 위한 quantization 방법에 대한 아이디어를 배울 수 있었습니다. 다만, VQ-Wav2vec을 통해 음성인식을 하려면 파이프라인에 따라 VQ-Wav2vec, BERT, Acoustic model까지 총 3번의 훈련과정을 거쳐야하는 단점이 있습니다. 저자들은 지금까지 나왔던 pre-trained feature를 acoustic model의 input으로 feeding하는 방식이 아니라, pre-trained 모델을 곧바로 fine-tuning 할 수 있는 End-to-End 방식의 모델을 future study로 삼았습니다. 이는 VQ-wav2vec의 후속작인 Wav2vec2.0 모델에서 알아볼 수 있는데요. 다음 포스팅에서는 Wav2vec2.0에 대해서 공부해보도록 하겠습니다.
Reference
VQ-Wav2vec : Self-Supervised Learning of Discrete Speech Representations
Comments