
Wav2vec 논문 꼼꼼 리뷰 - 1편
Wav2vec: Unsupervised pre-training for speech recognition
ABSTRACT
Wav2vec 은 Facebook에서 2019년 발표한 논문으로, 대용량의 unlabeled 오디오 데이터를 이용하여 acoustic model 학습을 개선하는데 도움이 되는 representation을 학습시켰습니다.
Wav2vec은 simple multi-layer CNN으로 구성되어 있으며, noise contrastive binary classification task를 통해 optimized 되었습니다.
해당 모델은 단 몇시간의 데이터만으로 WSJ (Wall street journal) 음성 데이터셋 기준 WER을 36%까지 낮췄으며, nov92 test set 기준 2.43%의 WER을 달성하며 기존 character-based SOTA(State of the art) 모델이었던 Deep speech2 모델의 성능을 뛰어넘었습니다.
INTRODUCTION
최근 SOTA모델들은 대용량의 데이터를 학습하여 최고의 성능을 내고 있습니다. 그러나, 대용량의 labeled data를 구하기란 그리 쉽지 않습니다. 이러한 문제를 해결하기 위해 대용량 labeled dataset을 통해 미리 학습된 pre-trained 모델을 가져와서 적은 데이터를 가지고 fine-tuning하는 방법이 대두되었습니다. Wav2vec에서는 대용량의 unlabeled 데이터와 labeled data를 활용하여 audio 신호의 general representations을 학습시킨 unsupervised pre-trained 모델을 만드는 것을 목표로 했습니다. 이는 대용량 labeled data를 얻기 힘든 음성데이터에 적용하기에 적합했다고 생각합니다.
Computer vision 분야에서는 이미 ImageNet과 COCO dataset으로 부터 representation을 학습한 unsupervised pre-trained 모델을 활용하여 Image captioning이나 pose estimation등의 task를 위한 모델을 초기화하는데에 유용하게 사용되고 있었습니다. NLP 분야에서도 unsupervised pre-trained 모델의 효과가 입증되었습니다 (text classification, phrase structure parsing, machine translation 등). Speech processing 분야에서는 주로 emotion recognition과 speaker identification, phoneme discrimintation에 초점이 맞춰져 있었고, 한 언어에서 다른 언어로 ASR representation을 옮기는(transfer) task에 활용 되었습니다. 그러나, unsupervised pre-trained모델을 활용하여 supervised speech recognition의 성능 향상에 적용된 사례는 없었습니다.
Wav2vec은 unsupervised pre-trained 모델을 supervised speech recognition에 적용시켜 성능을 향상시켰습니다. Wav2vec에서는 raw audio data를 input으로 받은 후에 CNN을 활용하여 general representation을 계산합니다. 그 후, contrastive loss를 이용하여 true feature audio sample과 negative audio sample을 구분할 수 있도록 학습시킵니다. 이 부분에 대해서는 뒤에 나오는 Objective 부분에서 조금 더 자세히 다뤄보겠습니다.
PRE-TRAINING APPROACH
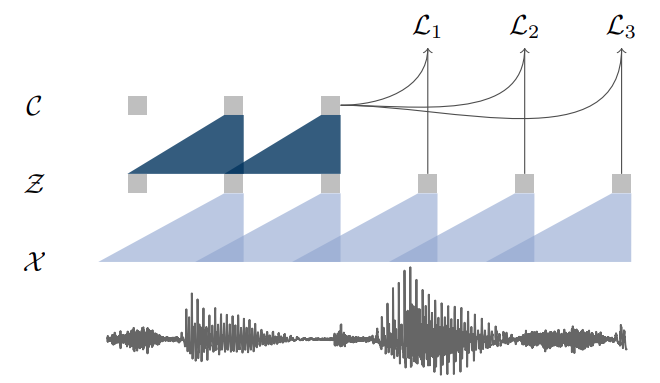
저자들은 인풋으로 주어진 audio signal로부터 signal context를 통해 future sample들을 예측할 수 있도록 모델을 최적화했습니다. 이 접근방법에서 문제가 되는 부분은 audio 데이터의 분포인 p(x)를 정확하게 모델링해야한다는 점인데요. 이는 사실 매우 어려운 문제입니다. 가령, t 시점의 future sample을 예측하기 위해 t 시점 이전에 주어진 audio signal context를 활용한다고 하면 결국
\[p( x_{t} | x_{t-1}, x_{t-2}, ... )\]를 최대화 해야하고, 이를 위해서는 각 xt-1 , xt-2 시점에서의 분포를 모두 정확하게 알아야 하기 때문입니다.
이 문제를 해결하기 위해 저자들은 raw speech sample을 저차원의 latent space 상으로 encoding 했습니다. 이때 latent space에 encoding된 audio signal을 feature representation(z) 라고 합니다. 이렇게 할 경우, t 시점의 future feature representation을 예측하기 위해 t 시점 이전에 주어진 feature representation context를 활용하는 문제로 바뀌게 됩니다. 예를들어, t = i-r 부터 t = i 시점까지의 feature representation context를 활용하여 t = i+k 시점의 future feature representation을 예측하는 문제는 아래와 같이 정의할 수 있습니다.
\[\frac{p(\bf{z}_{i+k} | \bf{z}_{i}, ... , \bf{z}_{i-r})}{p(\bf{z}_{i+k})}\]CNN을 통해 저차원의 latent space로 encoding된 representation (z)의 분포는 고차원의 복잡한 raw audio signal의 분포보다 상대적으로 훨씬 수월하게 구할 수 있습니다.
Model
Encoder network ( f : X -> Z )
CNN을 audio signal을 feature representation으로 인코딩하는 Encoder network는 5-layer Convolutional network로 구성되어 있습니다.
각 Kernel size는 (10, 8, 4, 4, 4)이고 stride는 (5, 4, 2, 2, 2)입니다. 인코딩을 할때에는 16KHz 오디오 신호의 30ms 구간에서 하나의 feature representation을 생성하며, 10ms의 stride를 가지고 진행합니다.
Context network ( f : Z -> C )
feature representation의 context를 얻기 위해 특정 구간의 feature representation을 하나의 representation context (c)로 변환합니다.
context를 만들기위한 receptive field size를 v라고 할때, 수식으로 나타내면 아래와 같습니다.
\[\bf{c}_{i} = g(\bf{z}_{i}, ... , \bf{z}_{i-v})\]원문에서는 Context network에 9개의 layer를 사용했으며 kernel size는 3, stride는 1로 두었습니다. Context network의 receptive field는 대략 210ms 정도라고 합니다.
최종적으로, encoder network와 context network는 512 channel의 causal convolution과 group normalization layer, 그리고 nonliearity를 위한 ReLU layer로 구성되어 있습니다. 특히, 저자들은 scaling이나 offset에 대해 robust하게 representation을 일반화할 수 있는 normalization 기법을 잘 선택하는 것이 중요하다고 말했습니다.
저자들은 대용량 dataset을 위한 wav2vec large 버전도 소개했는데요, 이 경우 인코더의 capacity를 늘리기 위해 두개의 추가적인 선형 변환을 추가하고 context network도 12개의 layer(kernel size = 2, 3, … , 13)로 늘렸습니다. 또한, 모델 수렴을 위해 aggregator에 skip connection을 도입했습니다. wav2vec large 버전에서는 receptive field도 약 810ms로 늘었습니다.
OBJECTIVE
Wav2vec에서는 contrastive loss를 이용하여 futre feature representation을 학습한다고 했는데요. 학습 과정을 구체적으로 하나씩 설명해보겠습니다. 아래 예시 그림과 함께 보시면 이해가 훨씬 쉽습니다.
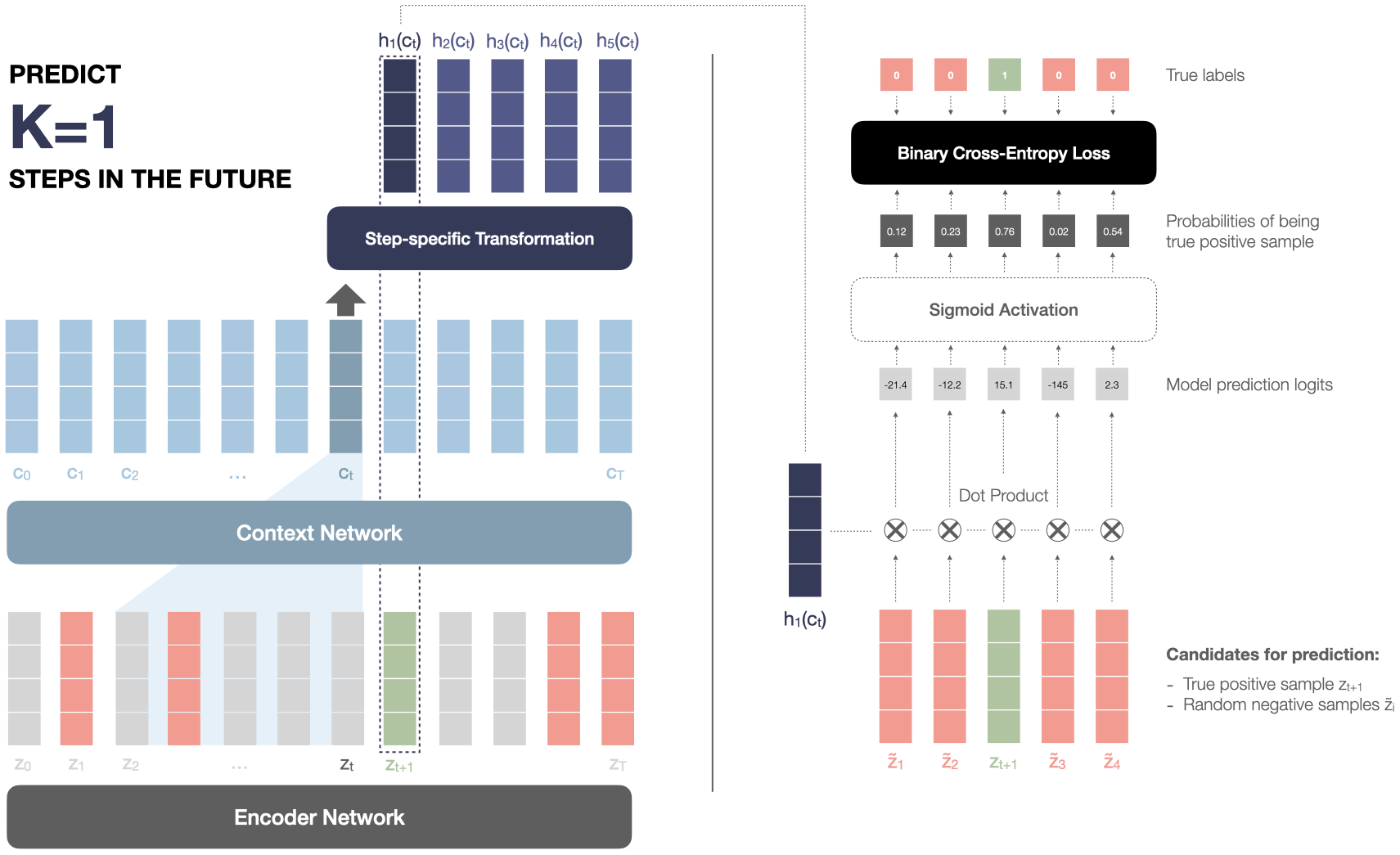
현재 시점을 t 라고 했을때, 현재시점으로부터 k step 이후의 freature representation을 예측한다고 해봅시다. 위 그림에서는 z2 부터 zt 까지의 feature representation을 이용하여 zt+1을 예측하고 있으므로, k = 1이 됩니다.
z2 부터 zt 까지의 feature representation은 context network를 거쳐 ct가 됩니다. 다음으로, 구해진 ct를 각 K번째 future step에 대하여 Affine transform을 적용하여 변환해줍니다. 이를 Step-specific transform라고 합니다. Affine transform은 수식으로 나타내면 아래와 같습니다. \(h_{k}(c_{i}) = W_{k}c_{i} + b_{k}\) 어디서 많이 보던 익숙한 수식이죠? Affine transform은 보시는 바와 같이 weight를 곱해 선형 변환을 한 후 Shifting 해주는 역할을 합니다. Shifting term (bk)이 들어 있기 때문에 엄밀히 말하면 비선형 변환이라고 할 수 있습니다. Affine 변환에 대해 더 자세히 알고 싶으신 분은 이 곳을 참고해주시면 되겠습니다.
이제 본격적으로 contrastive loss를 구해볼텐데요. contrastive loss를 간단히 정의하면 manifold 상에서 postive pair(true label)와의 거리는 가깝게하고, negative pair(noise label)과의 거리는 멀게 하는 기법입니다.
각 step에서 affine변환이 적용된 context vector(ct)를 K 스텝 이후의 future feature representation(zt) 와 10개의 distractor feature representation(z~1,2,3…,10)간 내적을 통해 유사도를 구합니다 (위 그림에서는 간소화를 위해 distractor feature representation이 4개입니다). 내적을 통해 유사도를 구한 후에, 각 유사도를 sigmoid function을 통해 확률로 변환한 후 True label과 Binary cross-entropy loss를 이용하여 학습합니다. 이 과정에서 latent space 상에서 true label (실제 미래에 오는 feature representation)과의 거리는 가까워지고, distractor label(feature representation과 상관없는 vector)와의 거리는 멀어지도록 학습이 되기 때문에 contrastive learning이 되는 것이죠.
이 모든 과정을 수식으로 나타내면 아래와 같습니다.
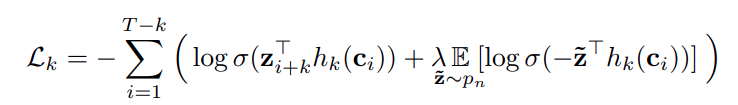
Lk : k번째 future step에 대한 Loss
T : Feature representation(z)의 Sequence length
σ(x) : 1/(1+exp(−x)) , Sigmoid function
σ(zTi+khk(ci)) : zi+k가 true sample이 될 확률
z~ : Distractor
p(n) : distractor를 뽑기 위한 proposal distribution
λ: negative(distractor)의 개수
참고로, distractor를 뽑을 때에는 각 audio sample의 Freature representation sequence중에서 uniform하게 10개를 뽑아서 사용하며, 이를 평균하여 negative pairs (distractor vector)에 전체에 대한 loss에 근사시킵니다. Feature representation sequence중 true label(z)가 있을 확률이 1 / T이므로 p(z) = 1 / T 입니다.
Lk는 각 sequence에서 k번째 future step에 대한 loss를 모두 더해서 계산되며, 전체 Loss는 모든 future step에 대한 loss의 합입니다. 즉, L = L1 + L2 + … +LK 이 됩니다.
원문에서는 future step 개수인 K가 12 이상일 경우 훈련 시간만 늘어나고 성능 개선은 없다고 말합니다.
훈련이 모두 끝나면, 학습된 context representation (ci)를 기존에 사용하던 log-mel filterbank feature을 대신하여 Acoustic model의 input으로 사용합니다.
훈련을 마쳤으니, 잘 훈련된 representation을 input으로 사용해서 얼마나 기존 supervised speech recognition 모델 성능을 향상시켰는지 알아봐야겠죠?
이 부분에 대해서는, 다음 포스팅인 2편으로 찾아뵙겠습니다.
Comments