
Wav2vec 논문 꼼꼼 리뷰 - 2편
Wav2vec: Unsupervised pre-training for speech recognition
이번 포스팅에서는 Wav2vec을 이용해서 supervised speech recognition의 성능을 얼마나 향상시킬 수 있었는지에 대해 얘기해 보겠습니다.
Wav2vec의 모델에 대한 개념과 설명에 대해 궁금하신 분은 저번에 포스팅했던 Wav2vec 논문 리뷰 1편을 참고해주시면 감사하겠습니다.
저번 포스팅과 관련해서 짧게 remind하고 넘어가자면, Wav2vec은 오디오 신호의 general representation을 학습함으로써 Acoustic Model에 도움이 되는 input을 제공하여 supervised speech recognition의 성능을 향상시키는 데에 목적이 있었습니다.
EXPERIMENTAL SETUP
DATA
저자들은 학습된 Wav2vec의 representation을 이용하여 phoneme recognition 모델에 적용했습니다. TIMIT dataset의 phoneme recognition을 위해 WSJ (81시간), Librispeech_clean (80시간), Librispeech (960시간) 및 전체 데이터셋의 조합을 사용했습니다. Wav2vec 모델과 비교할 baseline Acoustic Model (AM)은 25ms window에서 10ms stride 간격으로 80개의 log-mel filterbank coefficient를 뽑아서 사용했습니다. 최종 평가는 WER(word error rate)와 LER(letter error rate)를 통해 진행했습니다.
ACOUSTIC MODELS
저자들은 acoustic model의 훈련과 평가를 위해 facebook에서 개발한 wav2letter++ toolkit을 사용했습니다. TIMIT dataset에는 Character-based wav2letter++를 사용했는데, 7개의 연속된 convolution block(kernel size 5 with 1000 channels)으로 구성되었습니다. 비선형성을 위한 PReLU를 포함시키고 dropout rate는 0.7로 잡았습니다. 최종 representation은 39개의 phoneme에 대한 확률을 예측하도록 구성되었습니다. Acoustic model은 wav2letter에 포함된 ASG(auto segmentation criterion) loss와 momentum SGD optimizer를 사용했습니다. Learning rate는 0.12, momentum은 0.9, batch size는 16으로 두었습니다.
WSJ benchmark dataset에 대한 baseline 모델은 wav2letter++ 을 이용해 17개의 gated convolution layer로 구성되었습니다. 이 모델은 표준 영어 알파벳 31개, 아포스트로피 및 마침표, 반복문자 토큰 (ann => an1) 및 침묵 토큰 (|) 등을 예측하도록 구성되었습니다. plain SGD와 learning rate = 5.6, gradient clipping을 사용했고 batch size를 64로 1000 epoch을 학습시켰습니다. 또한, checkpoint에서 4-gram LM(language model)를 통한 validation WER을 기준으로 early stopping을 적용하고 모델을 선택했습니다.
모든 acoustic 모델은 8개의 NVIDIA V100 GPU를 사용하여 학습되었고, fairseq와 wav2letter++로 구현되었습니다.
DECODING
Acoustic model의 output을 decoding하기 위해 lexicon과 WSJ 데이터로만 훈련된 별도의 language model을 사용했습니다. 4-gram KenLM Language model과 word-based convolutional language model, 그리고 character based convolutional language model을 사용했습니다.
Decoding 과정은 아래의 수식을 maximize 하도록 진행했습니다.
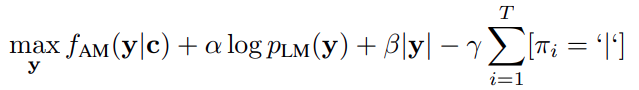
여기서 y는 word sequence를 의미하며, c는 wav2vec 모델의 context 또는 baseline 모델의 log-mel filterbank 입니다. fAM 과 pLM은 각각 acoustic model과 language model이며, π = π1, …, πL 는 word sequence의 character를 뜻합니다. Hyper-parameter α, β 그리고 r은 각각 language model, word penalty, silence penalty의 weight이며, random search로 최적화 했습니다. 결과적으로 Word based language model에서는 beam size = 4000 및 beam score threshold = 250을 사용했고, character based model에서는 beam size = 1500 및 beam score threshold = 40을 사용했습니다.
PRE-TRAINING MODELS
Pre-training은 fairseq toolkit의 pytorch로 구현했으며, Adam optimizer와 cosine learning rate schedule을 사용했습니다.
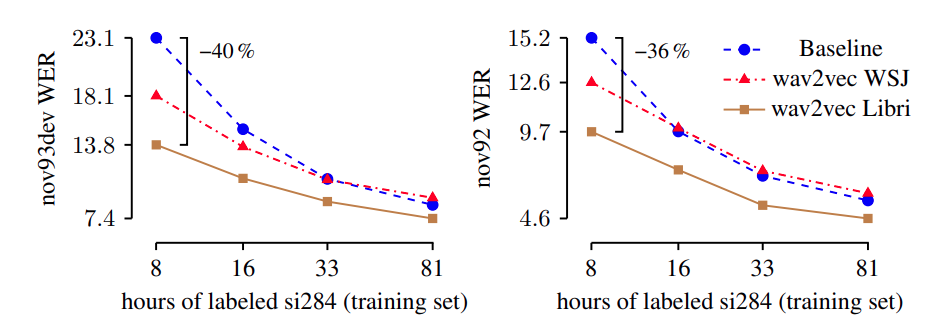
훈련 결과는 아래 그림과 같이 training set이 많을수록 wav2vec을 적용한 모델과 baseline 모델의 WER이 떨어지는 것을 볼 수 있으며, wav2vec을 사용한 모델의 성능이 더 좋은 것을 보여줍니다.
또한, 아래 그림은 TIMIT data에 대해 기존 모델들과 phoneme recognition 을 PER 기준으로 비교한 표입니다. 모든 모델은 CNN-8L(layer)-PReLU-do0.7(drop out = 0.7) architecture를 사용했다고 합니다.
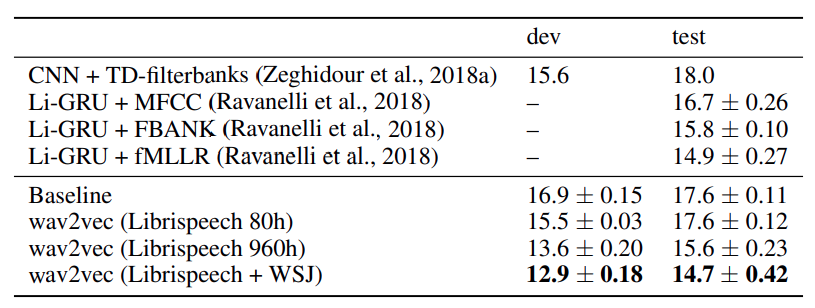
보시는 바와 같이, Wav2vec을 Librispeech와 WSJ를 모두 써서 학습했을때 가장 좋은 PER 성능을 보이는 것을 확인할 수 있습니다.
참고로, 저자들은 cropping을 통해 data를 augmentation 해서 성능 실험을 해보기도 했는데요, 150k의 crop size를 가질 때 가장 성능이 좋았다고 합니다.
CONCLUSIONS
지금까지 Wav2vec에 대해서 알아보았습니다. wav2vec은 unspervised pre-training model로써 off-line 음성인식 성능 향상에 크게 기여 했는데요. 개인적으로 논문을 정리하면서 아이디어나 방법에 대해 많은 인사이트를 얻었습니다. 현재는 후속작으로 wav2vec-vq와 wav2vec2.0 모델도 나와 있으니 차차 소개 드리도록 하겠습니다.
Comments